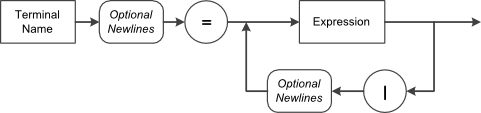

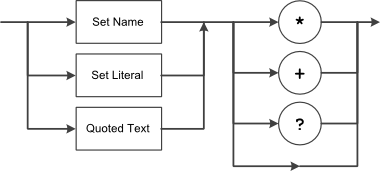
The notation is rather simple, yet versatile enough to express any terminal needed. Basically, regular expressions consist of a series of characters that define the pattern of the terminal.
Literal sets of characters are delimited using the square brackets '[' and ']' and defined sets are delimited by the braces '{' and '}'. For instance, the text "[abcde]" denotes a set of characters consisting of the first five letters of the alphabet; while the text "{abc}" refers to a set named "abc". Neither of these are part of the "pure" notation for regular expressions, but are widely used in other parser generators such as Lex/Yacc.
Sub-expressions are delimited by normal parenthesis '(' and ')'. The pipe character '|' is used to denote alternate expressions.
Either a set, a sub expression, or a single character can be followed by any of the following three symbols:
* |
Kleene Closure. This symbol denotes 0 or more or the specified character(s) |
+ |
One or more. This symbol denotes 1 or more of the specified character(s) |
? |
Optional. This symbol denotes 0 or 1 of the specified character(s) |
For example, the regular expression ab*
translates to "an a followed by zero or more b's" and [abc]+ translates to "an series of one or more a's,
b's or c's".
| Note: | When text is read by the Builder, all characters delimited by single quotes are
analyzed as literal strings. In other words, any text delimited by single quotes is
considered to be exactly as printed. This allows you to specify characters that
would normally be limited by the notation. For instance, when defining a rule, angle brackets are used to delimit nonterminals. By
typing '<' and '>',
you can specify these two characters without worrying about the system misinterpreting
them. A single quote character can be specified by typing a double single quote ''. In the case of regular expressions, single quotes allow you to specify the following characters: ? * + ( ) { } [ ] |
In practically all programming languages, the parser recognizes (and usually ignores) the spaces, new lines, and other meaningless characters that exist between tokens. For instance, in the code:
If Done
Then |
The fact that there are two spaces between the 'If' and 'Done', a new line after 'Then', and multiple space before 'Counter' is irrelevant.
From the parser's point of view (in particular the Deterministic Finite Automata that
it uses) these whitespace characters are recognized as a special terminal which can
be discarded. In GOLD, this terminal is simply called the Whitespace terminal and can be
defined to whatever is needed. If the Whitespace Terminal is not defined explicitly in the
grammar, it will be implicitly declared as one or more of the characters in the pre-defined Whitespace set: {Whitespace}+.
Normally, you would not need to worry about the Whitespace terminal unless you are designing a language where the end of a line is significant. This is the case with Visual Basic, BASIC and many, many others. The proper declaration can be seen in an example.
Block and line comments are common in programming languages. The Comment Terminal is often generated as a container for group. Since comments are considered whitespace, GOLD will set the Comment Terminal to "noise" if it is created.
| Declaration | Valid strings |
|---|---|
Example1 = a b c* |
ab, abc, abcc, abccc,
abcccc, ... |
Example2 = a b? c |
abc, ac |
Example3 = a|b|c |
a, b, c |
Example4 = a[12]*b |
ab, a1b, a2b, a12b, a21b,
a22b, a111b, ... |
Example5 = '*'+ |
*, **, ***, ****, ... |
Example6 = {Letter}+ |
cat, dog, Sacramento, ... |
Identifier = {Letter}{AlphaNumeric}* |
e4, Param4b, Color2,
temp, ... |
ListFunction = c[ad]+r |
car, cdr, caar, cadr,
cdar, cddr, caaar, ... |
ListFunction = c(a|d)+r |
The same as the above using a different, yet equivalent, regular expression. |
NewLine = {CR}{LF}|{CR} |
Windows and DOS use {CR}{LF} for newlines, UNIX simply uses {CR}. This definition will detect both. |