| Parsing Concepts |  |
|
| Character Sets - ASCII, ISO and Unicode |
| Main | |
|
|
Latest News |
|
|
Getting Started |
|
|
Screen Shots |
|
|
Download |
|
|
Documentation |
|
|
Contributors |
|
|
Contact |
| About GOLD | |
|
|
How It Works |
|
|
FAQ |
|
|
Why Use GOLD? |
|
|
Comparison |
|
|
Revision History |
|
|
Freeware License |
|
|
More ... |
![]()
ASCII
One of the most common character encodings is ASCII (American Standard Code for Information Interchange).
ASCII uses a total of 7 bits to store each character code - giving a total of 128 possible values. The first 32 characters of ASCII are reserved for control characters such as Line Feed, Carriage Return, and Form Feed (new page). Character #127 is interpreted as "delete" and was used in the past to delete information stored on tape and punch card media.
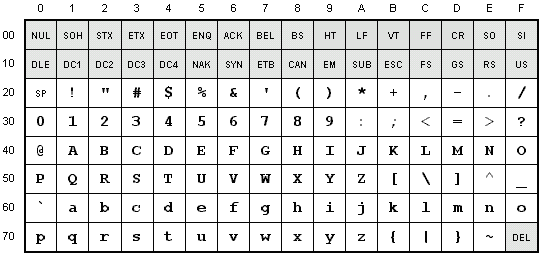
Although ASCII only contains 128 characters (only 95 not counting the control characters), it is sufficient for the English language.
ISO 646 - Making ASCII International
| ASCII, although sufficiently expressive for English, lacks many of the
characters found in other world languages such as German and Dutch. Many languages contain
accented versions of normal Latin characters and additional characters not found in
English. ASCII simply did not have the space to store these codes. To help resolve this issue, the International Standards Organization (ISO), in 1972, created the 646 specification. This specification defined a number of variants of the ASCII character set to use in different world states. The number of bits in the ISO-646 encoding is still 7-bit. To handle the additional characters, many of the symbols in ASCII were replaced. For instance, in the Dutch version, 646-DK, the backslash character was replaced with �. 646-US is identical to US-ASCII. For the most part, each version is compatible with one another. However, problems can arise if information was passed between different sets. For instance, if a 646-US text file containing the "[" character is moved to a 646-DE (German) system, the character will change to "�". |
|
||||||||||||||||||||||
Extended ASCII
|
In many cases, different companies extended ASCII (or ISO-646) to the full 8 bits available in the byte - creating a total of 256 possible values. However, the values from 128 to 256 varied greatly from company to company. For instance, in the early 80's each computer platform used the 128-256 range for its own particular needs - depending on the intended market. The Mattel Aquarius (known as the worst computer of all time) was designed primarily for games and home use (of both it was ill-suited). The extended characters contained cartoons, explosions, and box-drawing graphics. This was the only graphics capabilities of this system. The IBM-PC was designed to be easily used by different world states for both business and science. As a result, the extended characters contained additional Latin characters, mathematical symbols, and symbols for drawing graphical boxes.When necessary, characters in the 128-255 character range were modified for different languages. Like ISO 646, different versions of the IBM-PC/DOS encoding were created for different world states and different languages. These different versions of Extended ASCII were created by the Microsoft Corporation and are generally known as "Code Pages". The chart on the right contains a number of the different character encodings that were used throughout the world. The characters between 0-127 followed the ISO 646 encodings - meaning that the characters would not always match. In most cases, the various Code Pages became the de-facto standard. |
|
||||||||||||||||||||||||||||||||
The following two diagrams contain the Extended ASCII character codes for the IBM-PC and the Mattel Aquarius. Note the difference between the different characters in the "extended" range. Both companies assigned additional characters to the 0 - 31 range. When printed, they acted as normal control characters but could be POKE'd to the screen to display the graphical characters.
 CP437 - IBM-PC / DOS Extended ASCII |
 Mattel Aquarius Extended ASCII |
ISO 8859 - The 8-Bit Solution
| The existence of different, slightly incompatible, versions of ISO-646
and different versions of extended ASCII made is difficult to transport text between
systems. The first attempt to resolve this issue was in 1987 by International Standards Organization (ISO). The ISO 8859 specifications were not designed to create a single uniform character set, but to avoid the incompatibility of ISO-646. To accomplish this, rather than just use the first 7 bits of each byte, the 8859 character set was expanded to 8 bits - giving a total of 256 total codes. ISO could have accepted IBM-PC/DOS Extended ASCII as an international standard, but, instead, decided to create a new encoding. The codes between 0 and 127 were set to the same values in US-ASCII. This allowed easy portability of text - given that the lower 7-bits would be identical regardless of platform. The codes from 128 to 256, however, were specialized for different languages. While the first 128 codes would overlap between languages, the remaining 128 codes would not. ISO created a total of 16 different sets between 1987 and present time. The chart on the right contains each of the ISO 8859 sets along with its primary and secondary names. The 8859-12 set was rejected by the organization and numbering continued at 13. ISO 8859-16 was a revision of Latin-1 (a.k.a. "Western"). Various characters where replaced with those in higher demand such as the Euro. |
|
||||||||||||||||||||||||||||||||||
Windows-1252
Microsoft modified the ISO 8859-1 character set to use in its Windows Operating System. The characters between 128 and 159, which beforehand contained control characters, were modified to contain commonly needed characters. These characters included: Ÿ, the Euro symbol €, and the trademark symbol ™. This set is commonly, and vaguely, referred to as "ANSI".

Essentially, Windows-1252 is a superset of ISO 8859-1. Windows versions 3.1, 95, 98 and ME use this character set. The NT and XP series are strictly Unicode.
Unicode - The Universal Code
It became apparent after the ISO 8859 standard was created, that it was ill-suited for transmitting information between different languages. To resolve this problem, as well as the problems with earlier encodings, work began on the "universal" coding system. The system is called Unicode.
The Unicode Consortium, which is based in Mountain View, California (near San Francisco), published "The Unicode Standard" in 1991. The primary premise of the Unicode system is that each character should have a single and unique code. This value, called a "code point", would used universally - regardless of where in the world the system is used.
The original Unicode standard set the coding system to 16-bits - giving a total of 65536 possible code points. This was more than sufficient space to include all the characters for every language on the planet - and leave plenty of room for future expansion. The problems that plagued ASCII, IBM-PC/DOS Extended ASCII, ISO 646 and ISO 8859 would not affect Unicode.
The characters that shared the 128-255 range in ISO 8859 were given unique code points by the Unicode system. The first 256 codes are identical to ISO 8859-1 and conversion between the two is simple. The characters themselves were organized into different ranges within the 65636 code range. For instance, Greek characters are stored between 880 and 1023 (0x370 and 0x3FF); Hebrew characters are stored between 1424 and 1535 (0x590 and 0x5FF).
Unicode was developed at the same time as many of the latter ISO 8859 standards. It has, subsequently, replaced it on most modern operating systems. The Unicode Consortium works with the International Standards Organization (ISO) on the Unicode standard. However, the ISO/IEC 10646 standard is considered a subset of the Unicode standard. While ISO/IEC 10646 contains the same code points as Unicode, it does not contain additional information such as how the character is displayed and other metrics. In other words, ISO simply validated the Unicode Consortium standard for international use.
Beyond 16-bit
| In 2001, the Unicode Consortium released version 3.1 of the Unicode
encoding specification. At this point, the 16-bit code range was expanded to 21-bits which
made it possible to store over 1 million different code points. The system was subdivided into different logical "planes" that contain different broad classes of characters. The initial 65536 characters of Unicode were organized into the Basic Multilingual Plane (BMP). This set includes all characters that are part of modern written languages and common symbols such as icons. |
|
||||||||||||||
Plane 1, the Supplementary Multilingual Plane (SMP), is used to store characters that are part of historical languages such as Linear B. Musical and rare mathematical characters are also stored here.
Plane 2, the Supplementary Ideographic Plane (SIP), is used to store over 40,000 rare historical Chinese characters.
Plane 14 is used to store a number of nonrecommended and experimental tag symbols. The nature of this plane is nebulous and will, no doubt, change over time.
Planes 15 and 16 are open for private use.
Unicode Character Encoding
| Since Unicode is a multiple-byte encoding standard, The International Standards Organization (ISO), in the ISO/IEC 10646 specification, also defined two different Universal Character Sets (UCS) to store Unicode code points. Essentially, both UCS encodings are subsets of the UTF encoding. |
|
||||||||||||
UCS-2 and UCS-4
UCS-2, like the original version of Unicode, is primarily 16-bit. As expected, UCS-2 is only able to store the Basic Multilingual Plane (the first 65536 Unicode Characters).
UCS-4 encoding uses a total of 32-bits to store each character code. The full Unicode encoding can currently be represented with only 21 bits, which makes UCS-4 a particularly inefficient format. However, since computers generally store integer values in powers of 2, 32-bit integers are common on practically all platforms while 24-bit variants are exceedingly rare.
UTF-16
UTF-16 is almost identical to the UCS-2 format with some, very important, exceptions. This format usually stores each character code using 2-bytes like UCS-2, but also provides override sequences for encoding characters that are not part of the Basic Multilingual Plane. This allows the system to represent the normal Unicode characters using 16-bit, but also can provide the representation of Plane 1 and Plane 2 characters.
| UTF-16 also supports different byte ordering sequences. To accomplish this, every transmitted UTF string is preceeded by a Byte Order Mark (BOM) which tells the decoder the byte ordering of the following Unicode code points. The BOM is 2-bytes - with one byte containing FF and the other containing FE. 0xFFFE alerts the decoder that the information is stored in Little Endian; 0xFEFF is for Big Endian. |
|
||||||
Since practically all real-world Unicode characters are part of the Basic Multilingual Plane, UCS-2 is usually sufficient. However, UTF-16 has the benefit of providing a method for supporting the full Unicode encoding. As a result, UTF-16 is predominately used in most systems that support Unicode. Both Windows NT / XP and Linux use UTF-16 internally.
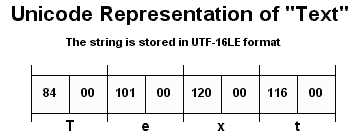
Note that the most significant byte (the second listed in Little Endian) will contain a 0 in for all ASCII characters.
UTF-8 and UTF-7
| The UTF-8 format supports a number of override sequences such that each
code in the Unicode encoding can be represented using 8 bits. UTF-8 was designed
specifically so that a string can be represented without any issues caused by byte
ordering. The encoding also will not conflict with ASCII control characters - meaning that
the string can be stored in legacy programs that are strictly based on ASCII and use the
null-character to terminate strings. UTF-8 is popular for transmitting Unicode information over the Internet and, more notabily, e-mail. Unfortunately, the number of e-mail clients that support Unicode varies and most information sent via e-mail is done using ISO 8859 or Windows-1252. UTF-7 is a 7-bit variant of UTF that uses a combination of Base64 (used in MIME) and override characters. However, since HTML-style encoding can also represent any Unicode code point, UTF-7 is rarely, if never, used. |
|
||||||||||
References
For more information, please see following links:
Special thanks to Mike Brown & Robert van Loenhout for their help.