| Parsing Concepts |  |
|
| What is a Parser? |
| Main | |
|
|
Latest News |
|
|
Getting Started |
|
|
Screen Shots |
|
|
Download |
|
|
Documentation |
|
|
Contributors |
|
|
Contact |
| About GOLD | |
|
|
How It Works |
|
|
FAQ |
|
|
Why Use GOLD? |
|
|
Comparison |
|
|
Revision History |
|
|
Freeware License |
|
|
More ... |
![]()
Programming Languages
When a software engineer designs and writes a program, it is often in one of the many modern programming languages available. Rather than taking on the rather tedious task of writing the program using the actual instructions used by the computer processor, the logic and behavior of the program are expressed using human-like and English-like terms. Whether the programming language is C++ or COBOL, the representation of which actions the program is to perform and how they are actually implemented differs greatly.
Programming languages are classified by their "generation". The first programs were written in machine code - since no other programming technology had been developed. If another computer processor was designed with the same basic instruction set, but a slightly different machine code format, programs had to be completely rewritten. This lead to the development of "second generation" programming languages: assemblers. Assemblers display each instruction using a keyword rather than the binary format. This gives a layer of abstraction between the machine code and the instruction set itself. Programs became far easier to read and write.
The disadvantage to the second generation languages was that programs could not be ported to other platforms. As a result, computer scientists designed the first "third generation" programming language: FORTRAN. Though it is not used much today, its effect on the computer industry was great. Programs could be written in human-like and English-like terms and then later compiled and executed on different machines. When most programmers use the term "programming language", they are referring to the third generation languages such as C++, COBOL, Visual Basic, Java and Delphi.
There is, however, a catch. To convert a modern third generation language to machine code, those human-like and English-like terms must be broken down into their different logical units. This is the job of a parser.
Parsers
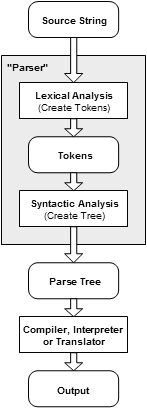 While the text of a
program is easy to understand by humans, the computer must convert it into a form which it
can understand before any emulation or compilation can begin.
While the text of a
program is easy to understand by humans, the computer must convert it into a form which it
can understand before any emulation or compilation can begin.
This process is know generally as "parsing" and consists of two distinct parts.
The first part is the "tokenizer" - also called a "lexer" or "scanner". The tokenizer takes the source text and breaks it into the reserved words, constants, identifiers, and symbols that are defined in the language. These "tokens" are subsequently passed to the actual 'parser' which analyzes the series of tokens and then determines when one of the language's syntax rules is complete.
As these completed ![]() rules
are "reduced" by the parser, a tree following the language's grammar and
representing the program is created. In this form, the program is ready to be interpreted
or compiled by the application.
rules
are "reduced" by the parser, a tree following the language's grammar and
representing the program is created. In this form, the program is ready to be interpreted
or compiled by the application.
Modern bottom-up parsers use a Deterministic Finite Automaton (DFA) to implement the tokenizer and a LALR(1) state machine to parse the created tokens. Practically all common parser generators, such as the UNIX standard YACC, use these algorithms.
The actual ![]() LALR(1)
and
LALR(1)
and ![]() DFA algorithms
are easy to implement since they rely on tables to determine actions and state transition.
Consequently, it is the computing of these tables that is both time-consuming and complex.
DFA algorithms
are easy to implement since they rely on tables to determine actions and state transition.
Consequently, it is the computing of these tables that is both time-consuming and complex.
The GOLD Parser Builder performs this task. Information is read from an source grammar and the the appropriate tables are computed . These tables are then saved to a file which can be, subsequently, loaded by the actual parser engine and used.