| Parsing Concepts |  |
|
| Deterministic Finite Automata |
| Main | |
|
|
Latest News |
|
|
Getting Started |
|
|
Screen Shots |
|
|
Download |
|
|
Documentation |
|
|
Contributors |
|
|
Contact |
| About GOLD | |
|
|
How It Works |
|
|
FAQ |
|
|
Why Use GOLD? |
|
|
Comparison |
|
|
Revision History |
|
|
Freeware License |
|
|
More ... |
![]()
Essentially, regular expressions can be used to define a regular language. Regular languages, in turn, exhibit very simple patterns. A deterministic finite automaton, or DFA for short, is a method if recognizing this pattern algorithmically.
As the name implies, deterministic finite automata are deterministic. This means that from any given state there is only one path for any given input. In other words, there is no ambiguity in state transition. It is also complete which means there is one path from any given input. It is finite; meaning there is a fixed and known number of states and transitions between states. Finally, it is an automaton. The transition from state to state is completely determined by the input. The algorithm merely follows the correct branches based on the information provided.
A DFA is commonly represented with a graph. The term "graph" is used quite loosely by other scientific fields. Often, it is refers to a plotted mathematical function or graphical representation of data. In computer science terms, however, a "graph" is simply a collection of nodes connected by edges.
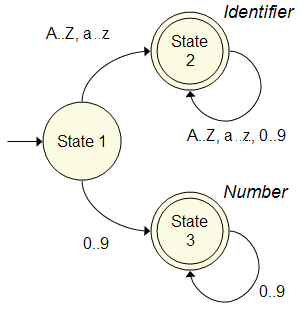 Most parser engines, including the GOLD Parsing System,
use a DFA to implement the tokenizer. This part of the engine scans the input and
determines when and if a series of characters can be recognized as a token.
Most parser engines, including the GOLD Parsing System,
use a DFA to implement the tokenizer. This part of the engine scans the input and
determines when and if a series of characters can be recognized as a token.
The figure to the right is a simple Deterministic Finite Automata that recognizes common identifiers and numbers. For instance, assume that the input contains the text "gold". From State 1 (the initial state), the DFA moves to State 2 when the "g" is read. For the next three characters, "o", "l" and "d", the DFA continues to loop to State 2.
By design, the tokenizer attempts to match the longest series of characters possible before accepting a token. For example: if the tokenizer is reading the characters "count" from the source, it can match the first character "c" as an identifier. It would not be prudent for the tokenizer to report five separate identifiers: "c", "o", "u", "n" and "t".
Each time a token is identified, it is passed to the ![]() LALR parse engine and the tokenizer restarts at the initial state.
LALR parse engine and the tokenizer restarts at the initial state.
For more information, please refer to the following:
- Loudan, Kenneth C. (1997). Compiler Construction, PWS Publishing Company, 20 Park Plaza, Boston, MA 02116-4324
- Appel, Andrew W. (1998). Modern Compiler Implementation in C. Cambridge University Press, 40 West 20th Street, New York City, New York 10011-4211
- Fischer, Charles N. & LeBlanc Jr., Richard J. (1988). Crafting a Compiler, The Benjamin/Cummings Publishing Company Inc., 2727 Sand Hill Road, Menlo Park, California 94025
- ... or just search for "Deterministic Finite Automata" on the Internet.